{kind=link}
Leadership In Test: Service Testing

Editor's Note: Welcome to the Leadership In Test series from software testing guru & consultant Paul Gerrard. The series is designed to help testers with a few years of experience—especially those on agile teams—excel in their test lead and management roles.
In the previous article, we looked at the changing role of testers and how to foster better collaboration with your colleagues. In this article, we’ll get into the nuts and bolts of testing a web application’s performance, reliability, and manageability. AKA service testing.
Sign up to The QA Lead newsletter to get notified when new parts of the series go live. These posts are extracts from Paul’s Leadership In Test course which we highly recommend to get a deeper dive on this and other topics. If you do, use our exclusive coupon code QALEADOFFER to score $60 off the full course price!
Hello and welcome to another chapter in the Leadership In Test series. This week we’re looking at service testing for web applications. We will cover:
- What Is Service Testing?
- What Is Performance Testing?
- Reliability/Failover Testing
- Service Management Testing
Let’s begin.
What Is Service Testing?
The quality of service that a web application provides could be defined to include all its attributes such as functionality, performance, reliability, usability, security and so on.
However, for our purposes here, we are separating out three particular service objectives that come under the scrutiny of what we will call ‘service testing’. These objectives are:
- Performance: the service must be responsive to users while supporting the loads imposed upon it.
- Reliability: if designed to be resilient to failure, the service must be reliable and/or continue to provide a service even when a failure occurs.
- Manageability: the service must be capable of being managed, configured or changed without a degradation of service being noticeable to end users. Manageability, or operations testing, aims to demonstrate that system administrative, management, and backup and recovery procedures operate effectively.
In all three cases, we need to simulate user load to conduct the tests effectively. Performance, reliability, and manageability objectives exist in the context of live customers using the site to do business.
The responsiveness (in this instance, the time it takes for one system node to respond to the request of another) of a site is directly related to the resources available within the technical architecture.
As more customers use the service, fewer technical resources are available to service each user’s requests and response times will degrade.
Obviously, a service that is lightly loaded is less likely to fail. Much of the complexity of software and hardware exists to accommodate the demands for resources within the technical architecture when a site is heavily loaded.
When a site is loaded (or overloaded), the conflicting requests for resources must be managed by various infrastructure components such as server and network operating systems, database management systems, web server products, object request brokers, middleware and so on.
These infrastructure components are usually more reliable than the custom-built application code that demands the resource, but failures can occur in either:
- Infrastructure components fail because application code (through poor design or implementation) imposes excessive demands on resources.
- The application components may fail because the resources they require may not always be available (in time).
By simulating typical and unusual production loads over an extended period, testers can expose flaws in the design or implementation of the system. When these flaws are resolved, the same tests will demonstrate the system to be resilient. QAs can take advantage of load testing tools to execute many of the processes defined below.
On all services, there are usually a number of critical management processes that have to be performed to keep the service running smoothly. It might be possible to shut down a service to do routine maintenance outside normal working hours, but most online services operate 24 hours a day.
The working day of the service never ends. Inevitably, management procedures must be performed while the service is live and users are on the system. These procedures need to be tested while there is a load on the system to ensure they do not adversely impact the live service aka performance testing.

What Is Performance Testing?
Performance testing is a key component of service testing. It is a way of testing how a system performs in terms of responsiveness and stability under a particular workload. Here’s an overview of how it works:
- Performance testing consists of a range of tests at varying loads where the system reaches a steady state (loads and response times at constant levels).
- We measure load and response times for each load, simulated for a 15-30 minute period, to get a statistically significant number of measurements.
- We monitor and record the vital signs for each load simulated. These are the various resources in our system e.g. CPU and memory usage, network bandwidth, I/O rates etc.
We plot a graph of these varying loads against the response times experienced by our “virtual” users. When plotted, our graph looks something like the figure below.
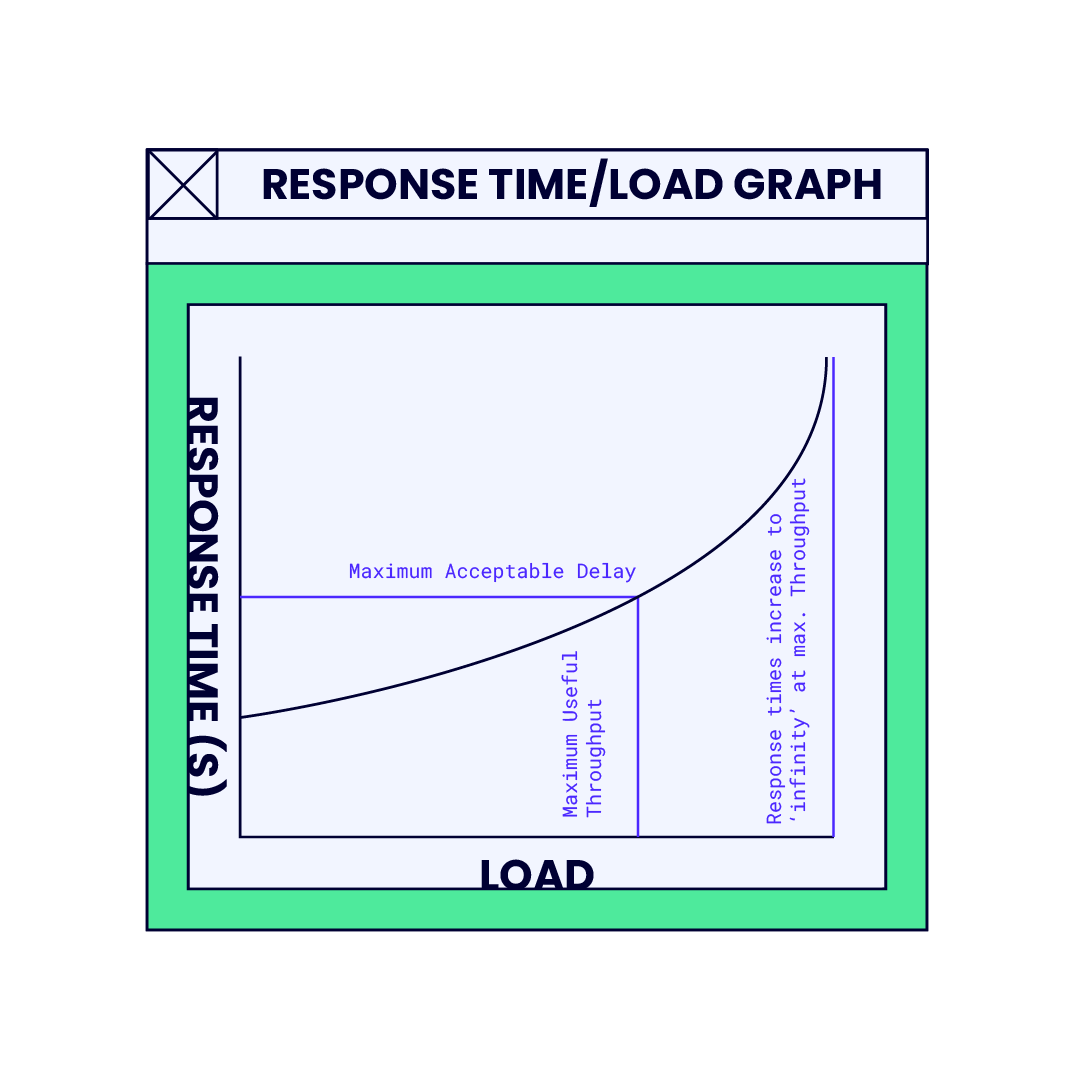
At zero-load, where there is only a single user on the system, they have the entire resource to themselves and the response times are fast. As we introduce increased loads and measure response times, they get progressively worse until we reach a point where the system is running at maximum capacity.
At this point, the response time for our test transactions is theoretically infinite because one of the key resources of the system is completely used up and no more transactions can be processed.
As we increase the loads from zero up to the maximum, we also monitor the usage of various resource types e.g. server processor usage, memory usage, network bandwidth, database locks, and so on.
At the maximum load, one of these resources is maxed out 100%. This resource is the limiting resource because it runs out first. Of course, at this point response times have degraded to the point that they are probably much slower than would be acceptable.
The graph below shows the usage/availability of several resources plotted against load.

To increase the throughput capacity and/or reduce response times for a system we must do one of the following:
- Reduce the demand for the resource, typically by making the software that uses the resource more efficient (this is usually a development responsibility).
- Optimize the use of the hardware resource within the technical architecture, for example by configuring the DBMS to cache more data in memory or by prioritising some processes above others on the application server.
- Make more of a resource available. Normally by adding processors, memory or network bandwidth and so on.
As you’re no doubt coming to realise already, performance testing needs a team of people to help the testers. These are the technical architects, server administrators, network administrators, developers, and database designers/administrators. These technical experts are qualified to analyze the statistics generated by the resource monitoring tools and judge how best to adjust the application, or tune or upgrade the system.
If you are the tester, unless you are a particular expert in these fields yourself, don’t be tempted to pretend that you can interpret these statistics and make tuning and optimization decisions. You’ll need to involve these experts early in the project to get their advice and buy-in and later, during testing, to ensure bottlenecks are identified and resolved.
Look out for the next article when we’ll take a deeper dive into how to manage performance testing.
Reliability/Failover Testing
Assuring the continuous availability of a service is likely a key objective of your project. Reliability testing helps to flush out obscure faults that cause unexpected failures. Failover testing helps to ensure that the designed-in failover measures for anticipated failures actually work.
Failover Testing
Where sites are required to be resilient and/or reliable, they tend to be designed with reliable system components with built-in redundancy and failover features that come into play when failures occur.
These features may include diverse network routing, multiple servers configured as clusters, middleware and distributed service technology that handles load balancing, and rerouting of traffic in failure scenarios.
Failover testing aims to explore the behaviour of the system under selected failure scenarios before deployment and normally involves the following:
- Identification of the components that could fail and cause a loss of service (looking at failures from the inside out).
- Identification of the hazards that could cause a failure and cause a loss of service (looking at threats from the outside in).
- An analysis of the failure modes or scenarios that could occur where you need confidence that the recovery measure will work.
- An automated test that can be used to load the system and explore the behaviour of the system over an extended period.
- The same automated test can also be used to load the system under test and monitor the behaviour of the system under failure conditions.
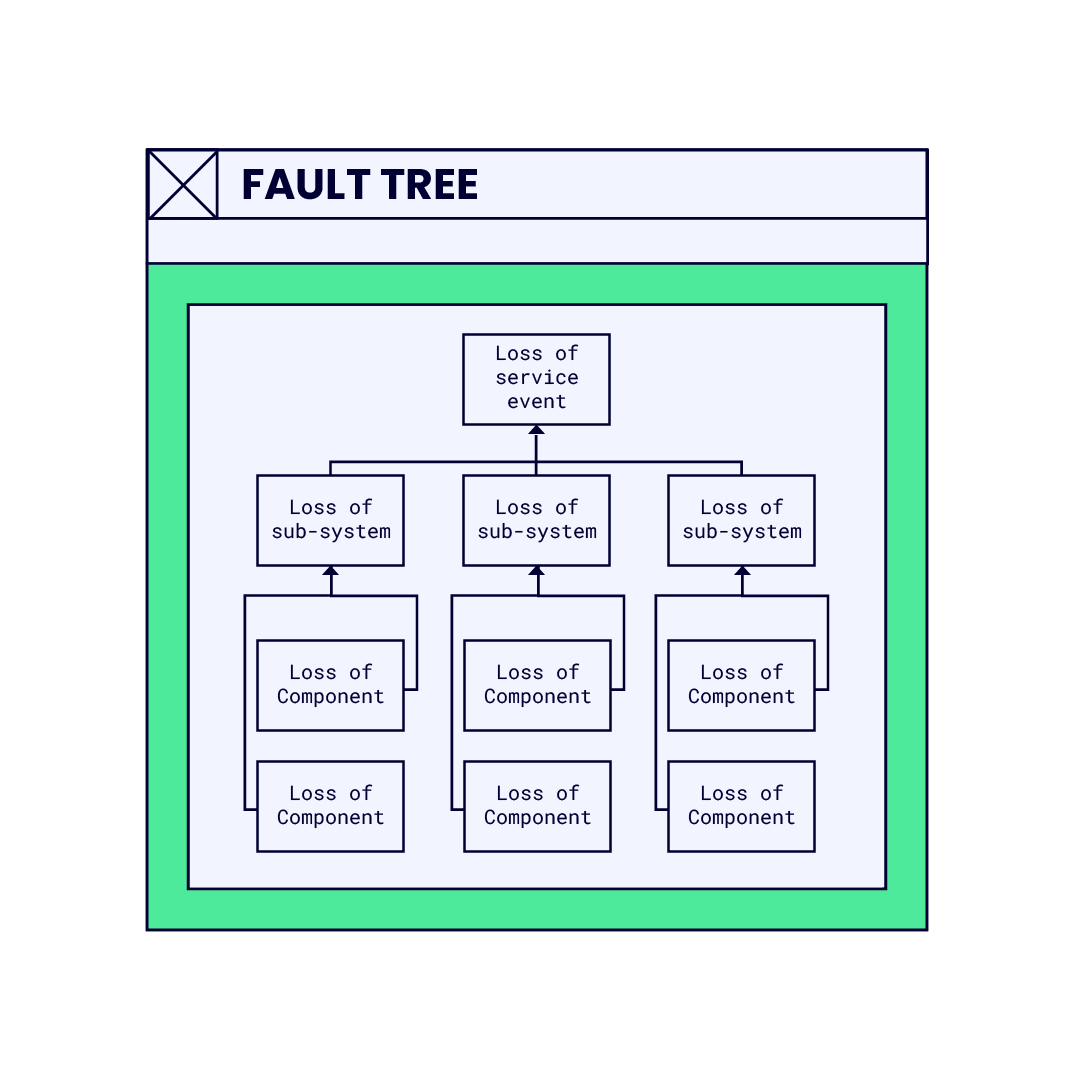
A technique called Fault Tree Analysis (FTA) can help you to understand the dependencies of service on its underlying components. Fault tree analysis and fault tree diagrams are a logical representation of a system or service and the ways in which it can fail.
The simple schematic below shows the relationship between basic component failure events, intermediate sub-system failure events, and the topmost service failure event. Of course, it might be possible to identify more than three levels of a failure events.
These tests need to be run with an automated load in order to explore the system’s behaviour in production situations and to gain confidence in the designed-in recovery measures. In particular, you want to know:
- How does the architecture behave in failure situations?
- Do load-balancing facilities work correctly?
- Do failover capabilities absorb the load when a component fails?
- Does automatic recovery operate? Do restarted systems “catch up”?
Ultimately, the tests focus on determining whether the service to end-users is maintained and whether the users actually notice the failure occurring.
Reliability (or soak) testing
Reliability testing aims to check that failures don’t occur under load.
Most hardware components are reliable to the degree that their mean time between failures may be measured in years. Reliability tests require the use (or reuse) of automated tests in two ways to simulate:
- Extreme loads on specific components or resources in the technical architecture.
- Extended periods of normal (or extreme) loads on the complete system.
When focusing on specific components, we are looking to stress the component by subjecting it to an unreasonably large number of requests to perform its designed function. It is often simpler to stress test critical components in isolation with large numbers of simple requests first before applying a much more complex test to the whole infrastructure. There are also specifically designed stress testing tools to make the process easier for QAs to execute.
Soak tests are tests that subject a system to a load over an extended period of perhaps 24, 48 hours, or longer to find (what are usually) obscure problems. Obscure faults often only manifest themselves after an extended period of use.
The automated test does not necessarily have to be ramped up to extreme loads (stress testing covers that). But we are particularly interested in the system’s ability to withstand continuous running of wide a variety of test transactions to find if there are any obscure memory leaks, locking, or race conditions.
Service Management Testing
Lastly, a word on service management testing.
When the service is deployed in production, it has to be managed. Keeping a service up and running requires it to be monitored, upgraded, backed up, and fixed quickly when things go wrong.
The procedures that service managers use to perform upgrades, backups, releases, and restorations from failures are critical to providing a reliable service so they need testing, particularly if the service will undergo rapid change after deployment.
The particular problems to be addressed are:
- Procedures fail to achieve the desired effect.
- Procedures are unworkable or unusable.
- Procedures disrupt the live service.
The tests should, as far as possible be run in a realistic way as possible.
Some Food For Thought
Some systems are prone to extreme loads when a certain event occurs. For example, an online business would expect peak loads just after they advertise offers on TV, or a national news website might be overloaded when a huge story breaks.
Consider a system you know well that was affected by unplanned incidents in your business or national news.
What incidents or events could trigger excess loads in your system?
Can (or could) you capture data from system logs that give you the number of transactions executed? Can you scale this event to predict a 1-in-a-100-year, or 1-in-a-1000 year, critical event?
What measures could you apply (or have applied) to either reduce the likelihood of peaks, the scale of peaks, or eliminate them altogether?
Sign up to The QA Lead newsletter to get notified when new parts of the series go live. These posts are extracts from Paul’s Leadership In Test course which we highly recommend to get a deeper dive on this and other topics. If you do, use our exclusive coupon code QALEADOFFER to score $60 off the full course price!
Suggested Read: 10 BEST OPEN SOURCE TEST MANAGEMENT TOOLS