{kind=link}
3 Key Server Monitoring Metrics To Track For System Health And Performance

Quality assurance requires a combination of proactive measures and efficient reactive protocols. With the proper balance, you can provide users excellent service and functionality on a server that’s available year-round. The only way to strike that equilibrium is to identify the most relevant server monitoring metrics.
But what could those be? That depends on your desired attributes, including those outlined in the Quality Maturity Model, and monitoring objectives. Still, there are a few health and performance metrics that QA engineers should always keep an eye on, no matter what.
By selecting the ideal server monitoring metrics from the outset, you can develop a performance baseline to use as a reference when health and performance issues inevitably arise.
In this brief guide, we'll look into why you should track these key metrics. Plus, you’ll get additional insights on their relevance and how to track them.
1. CPU Usage
One of the primary motivations for server monitoring is to keep an eye on infrastructure health and basic server performance. A critical part of that is the proactive diagnosis and mitigation of potential performance issues. The measurement of CPU and disk usage is central to these efforts. Hence, CPU usage is one of the most fundamental, commonly monitored performance metrics.
This metric is considered “host-based,” as it keeps a record of an individual machine’s ability to perform and remain stable. That said, monitoring CPU usage will entail a combination of passive and active monitoring. The latter is especially useful for controlled load testing, while the former collects measurements on the target during real traffic.
How To Measure CPU Utilization
Before you get started, you’ll need to:
- Select the particular drives you want to monitor.
- Determine where those drives are located.
- Make sure your data collector has access to your computer’s processes.
Once you’ve got that all setup, you’ll need to determine the sample rate at which you want to track these metrics. For example, you could measure CPU usage every 30 seconds or one minute.
There are a few different ways to track CPU usage, such as using your task manager or a command like wmic CPU get load percentage for Windows systems. However, when you’re trying to get a bird’s eye view of your server, it’s best to display this data on a dashboard.
Remember: CPU performance is influenced by hardware conditions, such as CPU temperature and fan speed. You may want to monitor these factors alongside the utilization (represented as a percentage) in these two states, ignoring idle.
| Busy | During this time, the CPU is executing a task. |
| I/O | This state isn’t busy, but it’s not idle either. Instead, the CPU could be waiting on an I/O operation to execute a task, typically by waiting to output data or receive data. |
Two key things you’ll want to monitor closely include Privileged Time and User Time, as the sum of these two will give you Processor Time, each defined as follows:
- Privileged Time: Percent of time processors use to execute non-user processes (i.e., kernel processes)
- User Time: Percent of time that processors use to execute user processes (e.g., command shell, email server, compiler)
- Processor Time: Total amount of time the CPU was busy
Keep in mind that exceeding 100% doesn’t always mean that a system is overloaded. For example, if you have a multiprocessor system, this just means that the sum of the two or more CPUs is greater than 100% (e.g., 50% and 60%). Watch their individual performances to maintain system health.
Along with CPU and disk utilization, waits are also considered essential in infrastructure health and performance monitoring.

Waits
Waits help inform you of how efficiently tasks are executed and alert you of any possible bottlenecks. But merely knowing the waits won’t do you any good. You’ll need to do additional research to identify the exact performance problem.
High waits are okay in bursts because you might have some intensive tasks running, but anything more than that is usually a cause for concern.
2. Server uptime
Your server is useless if it’s unavailable to your users. Thus, monitoring server uptime is non-negotiable. Anytime your server availability falls below 99.999% (the standard known as the “five nines”), you’ve got a serious problem on your hands.
Use the formulas below to get understandable, actionable insights from your monitoring efforts.
How To Measure Server Uptime
Here are a few core concepts to know when monitoring server uptime:
- Uptime: The amount of time your service or application is active and available to users. Formula: (Total time - Downtime)/Total time
- Mean time between failures (MTBF): The average time separating downtime incidents. Formula: (Total time - Downtime)/Number of downtime incidents
- Mean time to resolution (MTTR): The average amount of time required to resolve an outage. Formula: Total downtime/Number of downtime incidents
- Mean time to acknowledge (MTTA): The average amount of time needed to acknowledge a current outage. Formula: Total time to acknowledge/Number of downtime incidents
All of these metrics help to develop a big picture illustrating your infrastructure’s reliability and your team’s responsiveness.
So, for example, having a healthy MTTR and MTTA is good. But if you also have a high MTBF, you’ll need to investigate the root causes of your server’s downtime further. Otherwise, the company is still at risk of significant financial losses and damaging user trust.
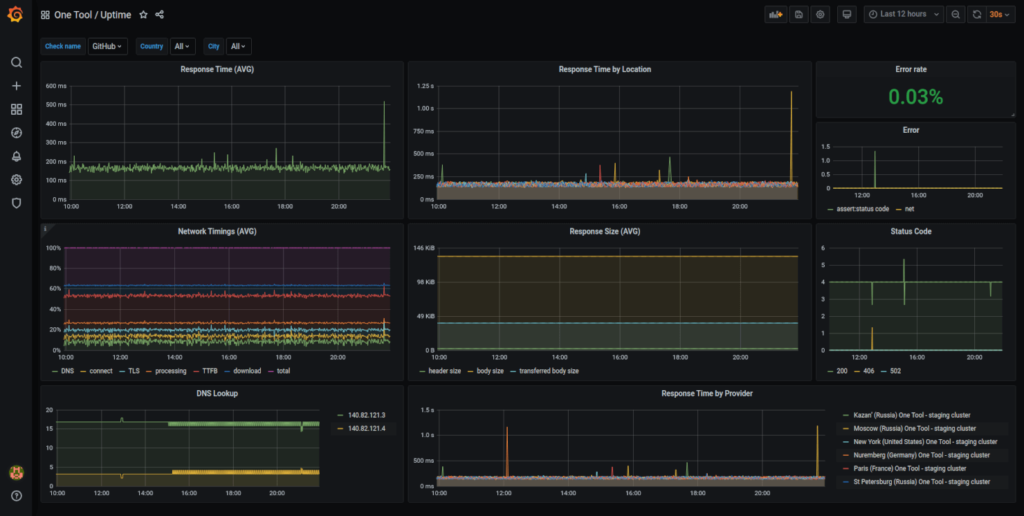
Ultimately, you must strive for the “five nines,” keeping downtime to a maximum of roughly five minutes per year. Grafana and Prometheus server monitoring software are both commonly recommended as user-friendly, easily accessible tools for this aspect of performance monitoring.
3. Transactions (and error rates)
You need a clear picture of just how much traffic your infrastructure supports at any given time. So, it’s essential to keep an eye on your transactions—or number of requests per second—and the corresponding average response time. This information can help you determine the amount of resources and capacity needed to run the server smoothly.
At the same time, tracking the error rate, or the percentage of failed requests relative to the total received, can provide further insights regarding your service’s load capacity. To maximize the value of this metric, it’s best to develop a baseline overtime via passive monitoring.
This is crucial to your ability to monitor trends. If you can look back and determine the maximum capacity and resources needed for smooth operation, you can act proactively to allocate those necessities and pinpoint infrastructure problems to reduce observed error rates and optimize your average response time.
How to Monitor Transactions and Error Rates
The following are reliable tools for passive performance monitoring techniques:
- Sniffers: These are designed to gather measurements at a “microscopic level” by “eavesdropping” on traffic flow on wired and wireless networks. Wireshark is one of the most widely accepted standards, which collects data on attributes like timestamp, MAC and IP address, time to live, and more. These can be used online or offline.
- Logging facilities: These are usually integrated into the operating systems and applications. They primarily collect information on the activities and events generated by applications for offline use.
One of the top ten web server monitoring tools that’s particularly good for monitoring transactions is Monitis. It’s an all-in-one monitoring system for servers, websites, and applications. It’s good for both Windows and Linux systems, and ideal for covering the basics, including uptime.
The objective and target of the monitoring efforts will influence the exact measurements and usage of these techniques.
Other Metrics to Monitor with Transactions
Response time and the total number of threads are directly related to transactions. These will inform you of how long your server takes to respond to a request, and the number of threads (which make the transactions happen) being used to handle all these requests.
Each thread uses up CPU time and RAM. Too many can lead to a sub-par performance. There’s quite a lot to monitor with these, including:
- The total number of threads in a web server or container pool, including these types:
- Active
- Idle
- Stuck
- Standby
- Pending user requests and queue length
You can typically measure server response time as Time to First Byte (TTFB). This is the number of milliseconds it takes for a browser to receive the first byte of a server response. Generally, anything more than five seconds is critical.
Choosing The Right Metrics For Server Performance Monitoring
There is a long list of metrics that you could be monitoring as you track the health and performance of your server, but the specific targets depend primarily on the objective of your monitoring efforts.
While some are best for gaining insights on your hardware and operating system’s load capacity, others are ideal for observing user activity. In any case, CPU, uptime, and transactions are fundamentals that can’t be overlooked.
As you advance as a QA lead and your objectives inevitably change, you'll undoubtedly add more server monitoring metrics to your dashboard. For more expert insights on which those should be and how to manage them, subscribe to the newsletter.