{kind=link}
Leadership In Test: Risk-based Testing

Editor’s Note: Welcome to the Leadership In Test series from software testing guru & consultant Paul Gerrard. The series is designed to help testers with a few years of experience—especially those on agile teams—excel in their test lead and management roles.
In the previous article we looked at the importance of test models. Here, we shall delve into the concept of risk and offer a risk-based testing manifesto you can apply to your own risk-based testing method.
Sign up to The QA Lead newsletter to get notified when new parts of the series go live. These posts are extracts from Paul’s Leadership In Test course which we highly recommend to get a deeper dive on this and other topics. If you do, use our exclusive coupon code QALEADOFFER to score $60 off the full course price!
Risks, if they materialise, have an adverse effect on our projects. Risk management is thinking what risks exist and taking actions to reduce their likelihood, eliminate them, or reduce their impact on our stakeholders’ goals.
In some businesses, risk management is practiced with engineering and mathematical precision. In software, it’s not possible to be very precise. Most organisations still don’t practice risk-based testing systematically. But there is good reason for this: once identified, software product risks are often terribly difficult to assess.
From the perspective of testing and assurance, a risk is a ‘mode of failure to be concerned about’. Risk-based testing is the practice of modelling potential system failure modes as product risks to support test scoping, scaling and prioritisation.
In this article I’ll offer a risk-based testing manifesto. We’ll look at classic risk-management and see how we can adjust it to be useful for testers. Finally, we’ll look at some practicalities and considerations that will help you to apply your own risk-based test method.
- Project, Process, And Product Risk
- A Risk-Based Testing Manifesto
- The Classic Approach To Risk
- Product Risk And Testing
- Practicalities
- Understanding Testing’s Risk Management Role
We’ll use this definition of risk: A risk is a threat to one or more of the stakeholders’ goals for a project and has an uncertain probability.
Project, Process and Product Risk
There are hundreds of books on risk and risk management that outline numerous approaches to managing risk at a project level. Typically, these approaches focus on what we’ll call project and process risks, with perhaps a single risk titled something like ‘failure to meet requirements’. Having a single requirement risk isn’t very helpful as it’s not as if you can prioritize one risk for testing.
There are three types of software risk.
Project risk: These risks relate to the project in its own context. Projects usually have external dependencies such as the availability of skills, dependency on suppliers, fixed deadlines or constraints such as a fixed-price contract. External dependencies are project management responsibilities.
Process risk: These risks relate primarily to the internals of the project and the project’s planning, monitoring and control come under scrutiny. Typical risks here are underestimation of project complexity, effort or the required skills. The internal management of a project such as good planning, progress monitoring and control are all project management responsibilities.
Product risk: Product risk is the main risk area of concern to testers. These risks relate to the definition of product, the stability (or lack) of requirements, the complexity of the product, and the fault proneness of the technology.
From now on, we’ll concentrate on product risks. We’ll use the term product risk as follows:
A product risk represents a mode or pattern of failure that would be unacceptable in a production environment.
A Risk-Based Testing Manifesto
In projects where risks will be taken (which is all of them, we think), testers need to provide visibility of the risks to management and propose reliable test methods to address these risks throughout a project.
This is the management task – to perform and/or oversee the following risk-based testing tasks:
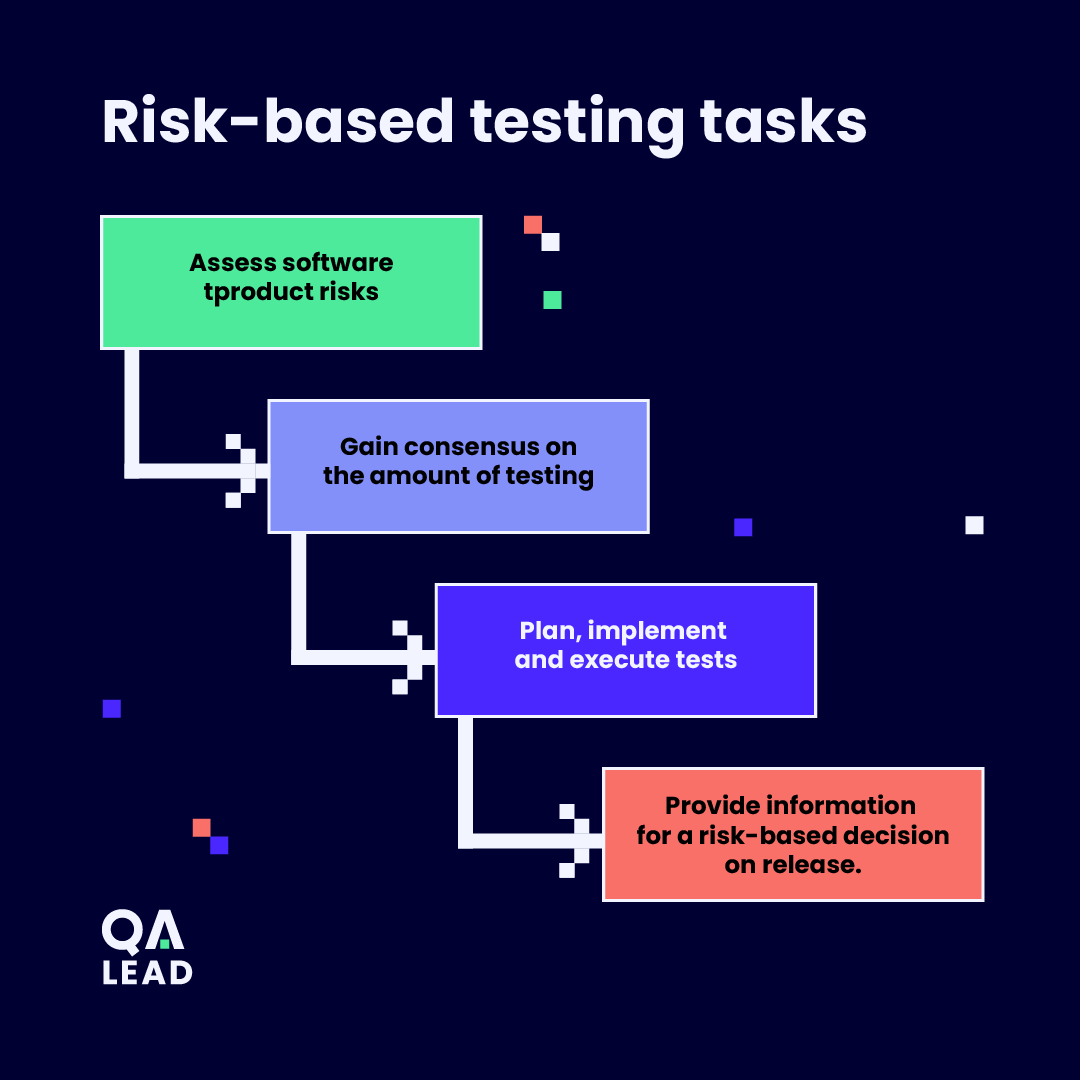
The Classic Approach to Risk
There are many variations, but the classic approach to risk attempts to be quantitative.

Probability, Consequence and Exposure
To assess a product risk we need to understand what the consequence of that mode of failure is. If a failure happens, we say the risk materialises. Then we ask “how serious is the risk?”, otherwise referred to as exposure.
To work out the exposure, we assess the risk in two dimensions:
- The probability (or likelihood) of a risk materialising. This value is typically expressed as a percentage between (but not including) zero and 100 percent.
- The consequence (or impact or loss) of a risk materialising. This is the potential cost of the damage if this mode of failure happens.
The exposure of a risk – how serious a risk it is – is calculated as the product of the probability and the consequence.
Exposure = Risk Probability X Risk consequence.
The classic approach to risk often lacks the technological support needed for efficient management. Modern test management solutions fill this gap by offering features tailored for risk-based testing.
Quantitative or Qualitative Scoring
Now, it is often difficult to predict the potential cost of a failure. Without further information, it is also next to impossible to predict the probability of a failure with much certainty. Hence most practitioners adopt semi-quantitative or qualitative scales for probability and consequence.
It is common to use numeric ranges from one to five for both scales giving us possible values for exposure of one to twenty-five. But few testers, developers or stakeholders assign these numbers with any confidence, so it is common to simply grade risk exposure directly using a scale of 1 to 5, or — even simpler — a red, amber, green assessment. Some go as far as simply saying risks are in-scope or out of scope, but we would suggest this is a simplification too far.
Whether you quantify or colour code the risks on the table, the critical aspect of risk assessments is not the scoring, but the conversations and debate you have when assigning and discussing the scores.
To misquote Eisenhower, the risk plan is nothing, risk planning is everything.
If you are asked to score risks using any more precision than scales of one to three (or five at a push) you should seriously consider whether the numbers you assign have any real value.
Numeric scoring might give an impression of scientific rigour but if the numbers are guesswork you are fooling yourself. If numbers expose differences of opinion e.g. a user says “five” and the developer says ‘“one!”, there’s a conversation to be had there as expectations or perceptions are clearly different.
Beware of using a simple in scope/out of scope scheme for risks. It might be clear which risks of concern are to be addressed by testing. However, projects learn over time, and often slip, so compromises have to be made. If risks are not prioritised in some way, you’ll have to review all risks of concern to decide which might need removing from or adding to scope.
We’ll discuss scoping, prioritisation and scaling in more detail in subsequent articles, so stay peeled.
Product Risk and Testing
The discussion of (product) risks will expose stakeholder’s fears of the likelihood of failure in critical areas of the project or system. Given a list of product risks, how do we translate that into action and specific plans for testing? Before we can answer that question, we need to understand a little better how testing affects or influences our risk assessments.
Testing Doesn’t Reduce Risk – It Informs Risks Assessments
You will often hear people suggest that ‘testing reduces risk’. That’s not true — testing can increase risk sometimes. The testing reduces risk mantra is borne of a lack of understating of both risks and testing.

Let’s say we have identified a risk that some feature or functionality might fail. We formulate a test and run it. The test might pass or might fail. How would a test pass or fail affect our assessment of risk?
Firstly, tests have no effect on our understanding of the consequence of a failure. The consequence of a failure is what it is and testing doesn’t change that.
There are four relevant outcomes of a test and impact on risk probability. These are summarised in this table:
| Risk Probability Increases | Risk Probability Decreases | |
| Test Passes | No. A passing test can only make us feel more confident a failure mode will not occur. (This assumes our tests are meaningful). | Yes, eventually. As we run more and more tests that pass, and we explore diverse scenarios, the likelihood of failure recedes. |
| Test Fails | Possibly, depending on the fail. But likelihood decreases over time. We predicted this mode of failure would happen; our test choice is vindicated. Thankfully, we can fix this now and focus our testing to reduce the risk of other failures of this type. | Not likely, unless we got our risk assessment wrong. |
Running tests that we associate with a particular risk gives us more and more information to refine our risk assessment. If tests fail, our choice is vindicated. When we fix and re-test, as tests pass our assessment of risk should reduce. But if we keep finding new/more bugs, we might reassess the risk as higher.
Consider this: if you run a test and the outcome doesn’t affect your probability assessment either way – it’s probably a worthless test.
Now you understand the potential of testing to inform our risk assessment, we can look at specifying tests from risk descriptions.
Risk-Based Test Planning
As testers, once we have identified a product risk of concern, we need to formulate a set of tests that demonstrate that mode of failure is less likely. Obviously, our test approach will be to stimulate the failure mode in as many ways as we can and in so doing, we either:
- Experience failures, detect bugs, and fix them (reducing the risk of that mode of failure) or
- Experience passes, and our confidence that a mode of failure is less likely increases.
Collectively, our tests focus on ways in which a selected mode of failure can occur. Suppose, for example, the risk was ‘failure to calculate a motor insurance premium correctly’. In this case, an appropriate test objective might be ‘demonstrate using the all-pairs technique for input variables that the system calculates the motor premium correctly’. This test objective can be given to a tester to derive a covering set of test cases using all-pairs, for example.
Practicalities
Now for some practical considerations surrounding risk-based testing.
What if stakeholders are not interested in helping with the risk assessment?
You might find that it’s hard to get stakeholder’s time to help you identify and assess risks and formulate your test plan.
What if there are multiple test options for a product risk?
This is almost always the case of course. For example, to test a feature of concern you could use any one of a range of test design techniques, or model the feature in some unique way and derive tests from that model. There are a range of coverage measures you might use to set a target. You might test a feature manually or using a tool or other technology.
We’ll look at how you might make choices in the next article, ‘How much testing is enough?’.
What if testing (to address a risk) costs too much?
Since there are almost always options, and there is no limit to how much testing one could apply to explore a risk and inform a risk assessment, a choice has to be made. Needless to say, some options will be deemed too expensive. So, when you present options to stakeholders, you’ll need to have at least one option that is affordable and one that might be unaffordable.
Again: we’ll look at how you might make choices in the next article, ‘How much testing is enough?’
If we test high risk features more, we test other features less, don’t we?
If the budget for testing is pre-set for a team, or the team size and number of testers is fixed, then the amount of testing people can perform is limited (in any fixed time scale or timeboxed period). So, if we place more emphasis on some features, then the testing on others must reduce. The coverage, or at least effort across features, varies with risk.
The way to look at this is that when a test fails and a bug is found in the system, then the severity assigned to the bug is likely to be closely related to the consequence of that failure (in production). More severe bugs get fixed because they are simply more important to stakeholders.
A product risk analysis highlights the areas where bugs, being important, are more likely to be fixed. So, using a risk analysis to highlight where testing happens, and/or where more testing is applied, means we are more likely to find important bugs and less likely to find bugs in features that stakeholders might care less about.
It would be nice to think that sometimes we can test everywhere in a more even fashion. But where resources and time are limited (and they always are, aren’t they?), a risk-based approach helps you to utilise tester time more effectively and efficiently.
What if testing isn’t the right response?
Before you commit time to figuring out a testing approach to a product risk in any detail, it’s important that non-testing options are also considered. For example, suppose there’s big concern that a system component might not perform well enough in production and response times or reliability are poor. Of course you could perform load tests and try and debug your way out of problems. But other options might be:
- Buy the component from a 3rd party, don’t build and take the risk.
- Re-architect the solution to distribute loads across multiple component instances.
- Offload the processing to a batch system on a copy of the data.
- Rather than implement a big-bang implementation of all users, take a phased approach to implementing customers region by region and monitor performance closely.
- And so on.
Often, a different course of action to prevent problems happening is more effective and economic than testing to find those problems later.
Understanding Testing’s Risk Management Role
Testing can reduce the risk of release. If we use a risk assessment to steer our test activity, the testers’ aim becomes explicitly to design tests to detect faults so they can be fixed and, in doing so, reduce the risk of a faulty product.
Fault detection reduces the residual risk of failures in live running, where costs increase very steeply. When a test finds a fault and it is corrected, the number of faults is reduced and consequently the overall likelihood of failure decreases.
One could also look at it in this way: the ‘micro-risk’ due to that fault is eliminated. But it must be remembered that testing cannot find all faults, so there will always be latent faults which are untouched and on which testing has provided no direct information.
However, if we focus on critical features and find faults in these, undetected faults in these critical features are less likely. The faults left in the non-critical features of the system are of lower consequence.
One final note: the process of risk analysis is itself risky. Risk analysis can both overestimate and underestimate the risks leading to less than perfect decision making. Risk analysis can also contribute to a culture of blame if taken too far.
Among other potential snags with risk analysis, you must understand that there is no such thing as absolute risk that could be calculated after the project is over. The nature of risks is that they are uncertain. Just like with the effectiveness of testing, the value of a risk analysis can only be determined with hindsight after the project is over.
And that’s it for our risk-based testing manifesto. The concept will reappear throughout the Leadership in Test series, so stay tuned for more articles!
Sign up to The QA Lead newsletter to get notified when new parts of the series go live. These posts are extracts from Paul’s Leadership In Test course which we highly recommend to get a deeper dive on this and other topics. If you do, use our exclusive coupon code QALEADOFFER to score $60 off the full course price!