{kind=link}
5 Types Of Black Box Testing Techniques + Examples

One of my favorite sayings is, “work smarter, not harder.” This, of course, applies to software testing too. This means that I want a way to do the least amount of work and bring the greatest value.
So let’s talk about black box testing techniques and how they can be applied to create test cases and to find the most important bugs in the application under test.

Need expert help selecting the right tool?
With one-on-one help, we guide you to your top software options. Narrow down your software search & make a confident choice.
What is Black Box Testing?
Let’s start by understanding what black box testing is—as opposed to white box testing. It’s a software testing type where the tester does not have access to the internal structure of the app they are testing. Instead, they can only access the inputs and outputs of the system and can test the functionality of the software based on the requirements specifications.
Keep in mind that black box testing only covers the external functionality of the software and does not verify the internal workings of the source code. That’s why it’s sometimes called “behavioral testing.” So it should be used together with white box testing, which focuses on testing the internal code. This way, you can feel more confident that the software is fully tested and as defect-free as possible.

5 Types of Black Box Testing Techniques
We use these black box testing techniques to increase the test coverage while, at the same time, reducing the number of test cases. By identifying the correct test data, we can create the smallest number of tests with the greatest coverage.
The techniques I’ll be talking about can be applied to all testing levels—including unit testing, integration testing, and system tests, as well as functional and non-functional testing.
1. Equivalence Partitioning
Equivalence class partitioning is a technique used in software testing to divide the possible inputs into a set of equivalence classes, or partitions, with the goal of finding and testing a representative set of inputs from each class. All the elements belonging to an equivalence class are expected to give out the same output, so testing a single value from the set should be enough.
This helps to reduce the number of test cases that need to be created and executed while still providing good coverage. The classes are defined based on functional or non-functional requirements and can take into account factors such as data types, ranges, and relationships between input values.
When defining the equivalence classes, you should always make sure to also include the invalid ones, too, to cover the negative test scenarios as well. In my experience, I’ve found that most defects are found when using invalid inputs rather than positive ones.
Let’s look at an example:
You have an optional field that only allows integer values between 1 and 10. You would have the following equivalence classes:
- no value (valid partition)
- values between 1 and 10 (valid partition)
- values smaller than 1 (invalid partition)
- values higher than 10 (invalid partition)
So you would need only 4 test cases - 1 for each partition. There is no added value from retesting the same partition with multiple values—if you tested for value 5, you would get the same results for values 4, 8, and so on.
2. Boundary Value Analysis
Boundary analysis is a technique used in software testing to identify and test the input values at or near the edge or "boundary" of the program's input domain. The idea is that these values are more likely to cause errors or unexpected behavior because they often involve special cases or edge cases that the program may not have been designed to handle properly.
For example, testing a program that accepts a range of integers between 1 and 100, the boundary values would be 1, 100, and all the values just outside the range, such as 0 and 101.
The two types of boundary testing are:
- Inner Boundary Testing: focuses on the input values that are just inside the edge of the input domain, such as the minimum and maximum values that are allowed.
- Outer Boundary Testing: focuses on the input values that are just outside the edge of the input domain, such as values that are slightly above or below the minimum and maximum allowed values.
Boundary analysis is an important technique for finding errors and ensuring that a program behaves correctly for all inputs, not just those in the middle of the input domain. This can help to identify and fix bugs that might otherwise go unnoticed.
3. Decision Table Testing
In decision table testing, we test the logic and behavior of software when multiple conditions are available. It is a way of representing the relationships between inputs and outputs in a tabular format. The table typically has columns for conditions and rows for the different combinations. For each row, you need to create a specific test case. The expected output for the test case should also be included in the table.
Let’s imagine a software requirement example where this technique can be applied: an app that calculates the cost of a purchase based on the item, quantity, and shipping method:
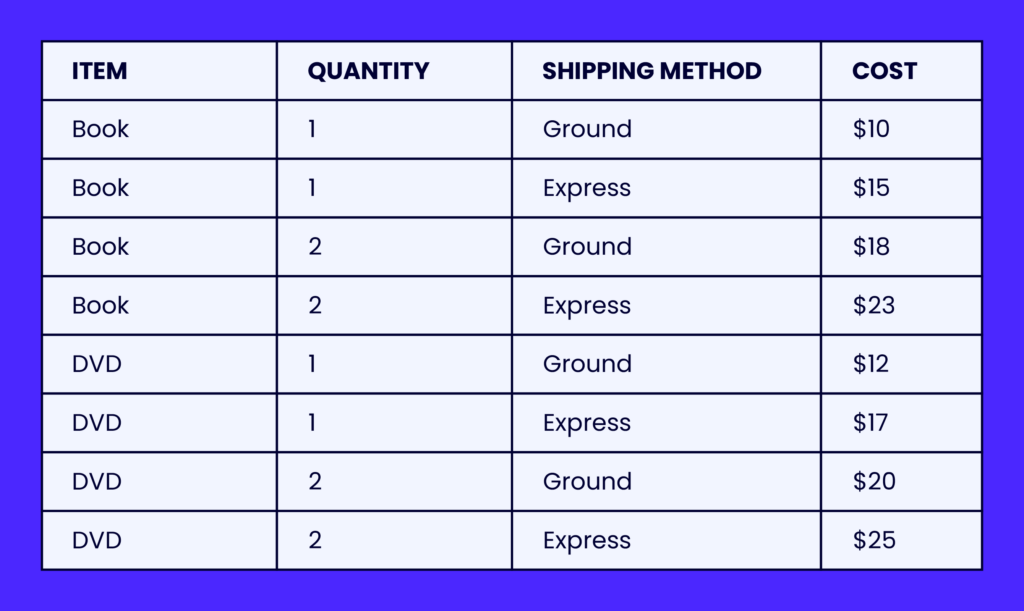
In this example, the Item, Quantity, and Shipping Method are the inputs, and the Cost is the output. The table shows all the possible combinations of inputs and the corresponding output in each case. By using this table, you can quickly identify the test cases and their expected results, making it easy to test and verify the available combinations.
Decision table testing is useful when a program has multiple inputs and conditions that interact with each other in complex ways. By breaking down the inputs and conditions into a table, it becomes easier to identify and test all the possible combinations and variations.
4. State Transition Testing
State transition testing is a black box testing technique where we test the behavior of a program as it transitions between different states or modes. A state is a condition or set of conditions in which the program can exist, and a transition is a change from one state to another. The idea behind state transition testing is to identify all the possible states and transitions that a program can go through, and then create test cases to verify that the program behaves correctly in each state and makes valid transitions between states.
An example of state transition testing would be for an e-commerce website where customers can add items to their cart, proceed to checkout, enter their payment information and shipping details, and finally place an order. The states in this example would be:
- Browsing products
- Adding items to cart
- Checking out
- Entering payment and shipping details
- Order confirmation
The transitions between these states would be:
- Browsing products -> Adding items to cart
- Adding items to cart -> Checking out
- Checking out -> Entering payment and shipping details
- Entering payment and shipping details -> Order confirmation
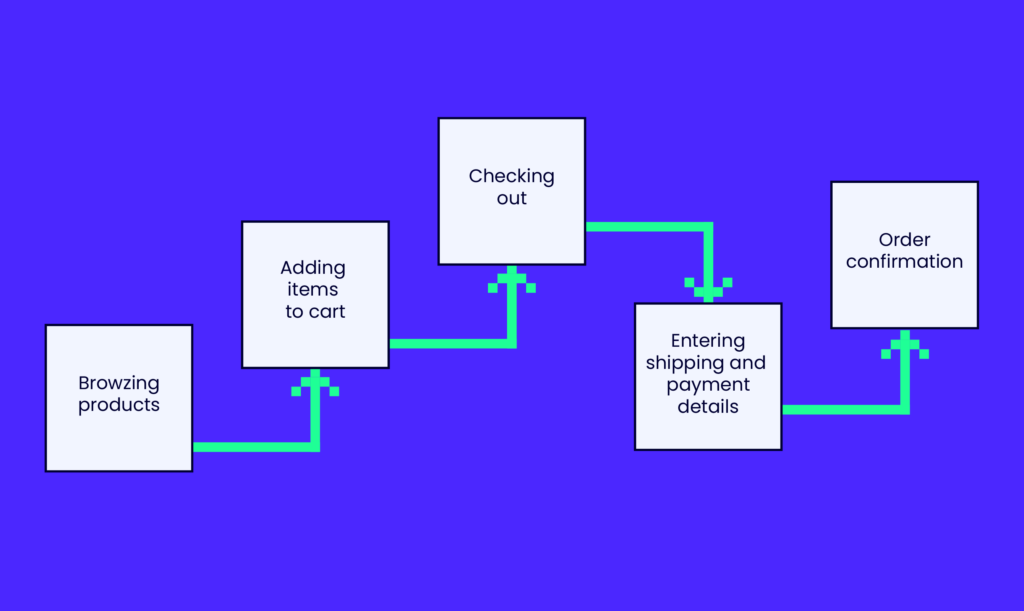
This technique helps to identify and test all the possible paths that a user can take through the system, and can help to find and fix bugs related to specific flows. State transition testing is particularly useful for testing systems with complex interactions, such as financial systems, e-commerce systems, or systems that control physical devices.
5. Pairwise Testing
Pairwise testing is a black box testing technique used to create test cases to cover all possible pairs of combinations of input values for a given set of parameters. It is used when the available number of inputs is high, which would make it extremely difficult to test all possible combinations between all of them.
Let's say we have an app with 3 fields: A, B, and C. Each field can accept 3 possible values: 1, 2, or 3.
With traditional testing methods, we would have to test 27 (3^3) possible combinations of inputs individually, to validate all possible combinations. This would be extremely time-consuming and inefficient.
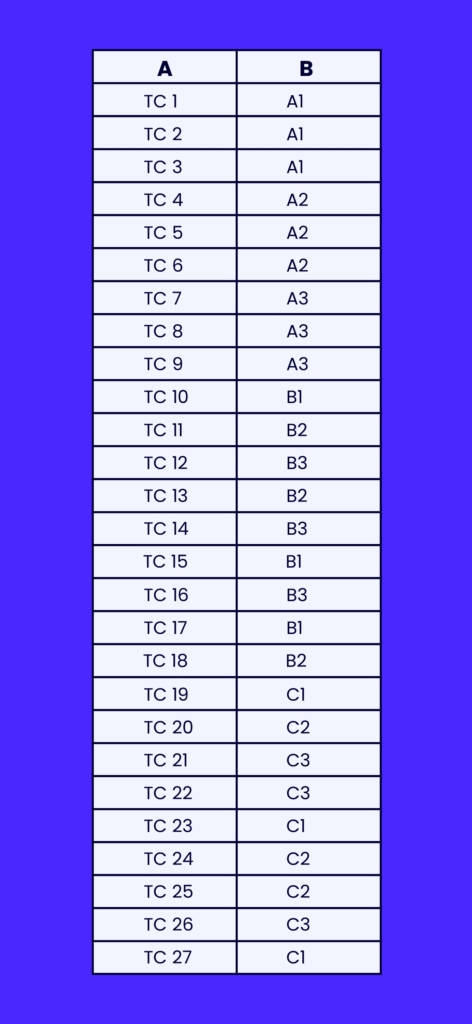
With pairwise testing, you can identify use cases that cover all possible unique combinations of inputs. This would look something like this:
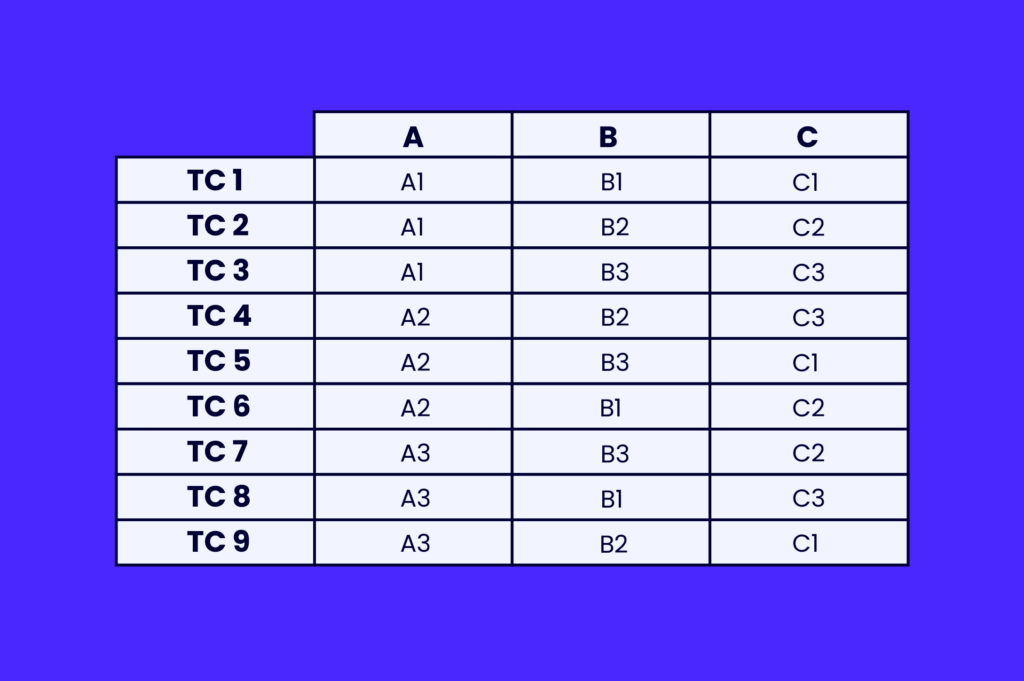
As you can see, the number of tests has been drastically reduced, from 27 to 9. The test coverage hasn’t changed, we are still ensuring that all possible combinations of values are taken into account.
There are several pairwise testing tools available to use. I’ll list below some examples:
- AllPairs: A tool for creating pairwise test cases based on user-specified parameter lists and constraints. It is available in both open-source and commercial versions.
- PICT (Pairwise Independent Combinatorial Testing): A tool that uses a genetic algorithm to generate pairwise test cases. It is available as an open-source tool.
- SmartBear TestComplete: A commercial test automation tool that includes built-in support for pairwise testing.
- Pairwise Test Case Generator: An open-source tool that is available on GitHub and can be used to generate pairwise test cases.
- Pairwise testing can also be generated using Excel or OpenOffice Calc using macros or plugins to generate your test cases.
These are just a few examples, and there may be other tools available as well. I recommend you research and evaluate the different options available and see which tool works best for your specific needs and requirements.
Need expert help selecting the right Testing Software?
If you’re struggling to choose the right software, let us help you. Just share your needs in the form below and you’ll get free access to our dedicated software advisors who match and connect you with the best vendors for your needs.
Final Thoughts
Using these techniques is a great way to achieve good coverage at any stage of the software development life cycle. It can be even better if you can add other types in your testing process, such as exploratory or error-guessing, compatibility testing, usability testing, and so on.
Also, if the resulting test cases end up in the regression testing suite, you should consider automating them—for UI tests you can use tools like Selenium, Cypress, and Appium, for API testing you can have integration tests written by the development team, or you can use tools such as Postman.
If you found this article useful, I suggest you subscribe to the QA Lead newsletter, where you will find out about all the new content and tutorials on quality assurance and testing.